Embeddings in Machine Learning
I’ve recently been tasked with applying machine learning and neural networks to classify documents at my day job. Everyday while working to solve this problem I have new realizations about this field which was completely foreign to me only a few months ago. I took what is called a top-down approach, which basically means diving in head first and trying to solve problems without necessarily understanding the ins and outs.
Interestingly enough this isn’t all that different than how I learned web
development. I started by viewing the source of a web page, then creating my own
.html file, followed by applying CSS and JavaScript to build what I wanted.
However, neural networks and machine learning require far more discipline than web development. While I would argue the tools, frameworks and blogs are equally available, the actual pieces are often just assumed or are given without any explanation or application.
What are Embedding Layers
One of these key components are Embedding Layers. Rutger Ruizendaal wrote a fantastic article explaining Embedding layers in far more detail than I will here. My goal is to hopefully help others who struggle on how to make them applicable.
An embedding can be thought of a way to provide dimension to anything. Commonly it is applied with word embeddings such as GloVe and Word2Vec. I found this difficult to grasp as those two projects provide dictionaries with 100, 200 and 300 dimensions.
I read and understood that those large dimensions were designed to provide context to each word in the vocabulary. This is done to provide similarities and distinctions to better understand the word within the context of a sentence or phrase. For instance, the company “Apple” and fruit “apple” are the same word but depending on the context are completely different entities.
How to Apply Embedding Layers

When discussed you’ll often read that embeddings can be applied to almost everything. But what? It makes sense with vocabulary but can they also be applied to something such as food or an ingredient? Yes!
An embedding can be thought of as a list of floats that align to a set of features
Let’s say we wanted to classify a recipe as Breakfast, Lunch,
Dinner or Desert. One way we might solve this is by using embeddings on each
of the ingredients of a recipe. This would allow us to extrapolate the type of
recipe beyond looking at the frequency of shared ingredients.
We could look at an ingredient by classifying features such as Citrus,
Sweet, Sour, Tangy, Solidity, and Water Saturation. Most ingredients
are not just one of these things, rather, they are a combination of all of them.
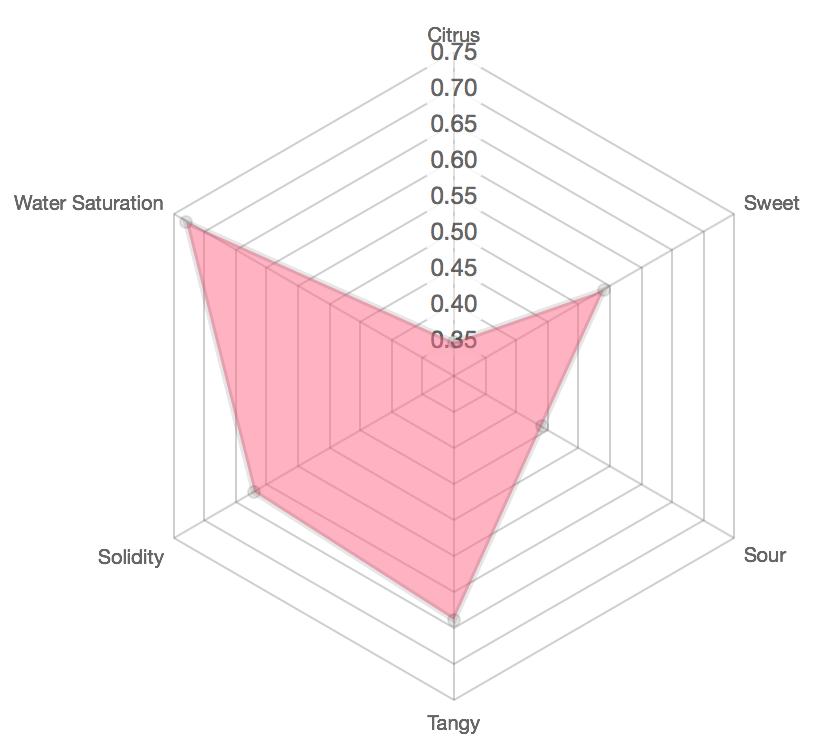
The radar chart to the left visualizes how I might embed the details of a tomato with the above features.
In code you would represent this as the following. The values themselves are relative to the feature they represent.
ingredients = {
'tomato': [
0.35, # Citrus
0.54, # Sweet
0.44, # Sour
0.64, # Tangy
0.62, # Solidity
0.73 # Water Saturation
],
'broccoli': [
0.02, # Citrus
0.09, # Sweet
0.13, # Sour
0.14, # Tangy
0.87, # Solidity
0.32 # Water Saturation
]
}
Why is this necessary
After giving this some thought I realized this is necessary since the neural network we are training (in my case at least) has no prior knowledge. It can only learn from the data we provide. This is a polar opposite to us. We have the ability to create ‘embeddings’ on everything we come into contact with. Whether it’s food, cars, software, television shows or even other people.
This is an important factor that I think can be easily overlooked. By understanding that everything is built up by many, small features we can learn how to represent our data to assist with training a successful neural network.
Off topic…
In my opinion as of 7/30/2018, the step to successful machine learning is trying to replicate the our own natural ability to collect information and make informed decisions. Neural networks never have 100% accuracy since we are modeling them after ourselves and we can expect nothing more considering our own limitations. I find this to be an interesting dynamic that generally isn’t shared with software development.