Who Knows Who or What?
A few years ago I had the opportunity to help build a social media platform designed to connect professionals with various connections. The idea being to index users based on companies or individuals they had previously mentioned having a connection to.
While this is a problem I still don’t fully understand it was especially difficult for me back then. I’m writing this post for my future self and for others facing a similar issue.
The Solution
I think the end goal to this problem is basically building a graph database that
has the following connections user -> (person, company or location). With this
design it is possible to perform a reverse lookup to find the fellow user with
the contacts you are looking for.
Problem #1: Classifying Texts
The platform I worked on was strictly driven by unlabelled text. Posts could be any of the following types Question, Announcement, Search, Poll and didn’t follow a template.
1. “Does anyone have any recommendations for restaurants in X city?”
2. “The company I work for is wanting to hire an intern for the summer. Please contact me at “x@y.com”
3. “I’m looking for a contact at X company to promote Y product.”
4. “Which of these products do you think provide the best lift X, Y or Z?”
All of these texts are hand written without any required structure. This makes classifying and therefore indexing the important information very difficult.
I think the way we solve this first problem is is by applying Part of Speech tagging overlayed with an intent parser. The idea is we look at the verbs in correlation to types of entities they are modifying/connected to. These two techniques should help us label the text.
Problem #2: Extracting Entities
Once we have labelled the text, next we need to extract the entities in question.
All of the above texts have important information to build our connections database. In the first text, a question, we ask for recommendations in a city. This is helps us identity that the user is likely making a trip to X city and probably knows or would like to meet people in that city.
This information compounds itself since we will have likely extracted entities from previous posts which would help us determine their likes and interests.
“The following people are from X city and also like A, B and C.”
This makes it realistic for us to create ‘answers’ or help other users find questions they may be able to answer.
Example Entity Extraction
Problem #3: Finding Answers
The last step to finding answers comes from inferring connections. This is probably best solved with word embeddings such as Word2Vec.
I think there’s a good possibility we can start with a pretrained model from the Wikipedia and/or Google News datasets. These models will help us gain insight into the people, companies or locations and figure out how they are related.
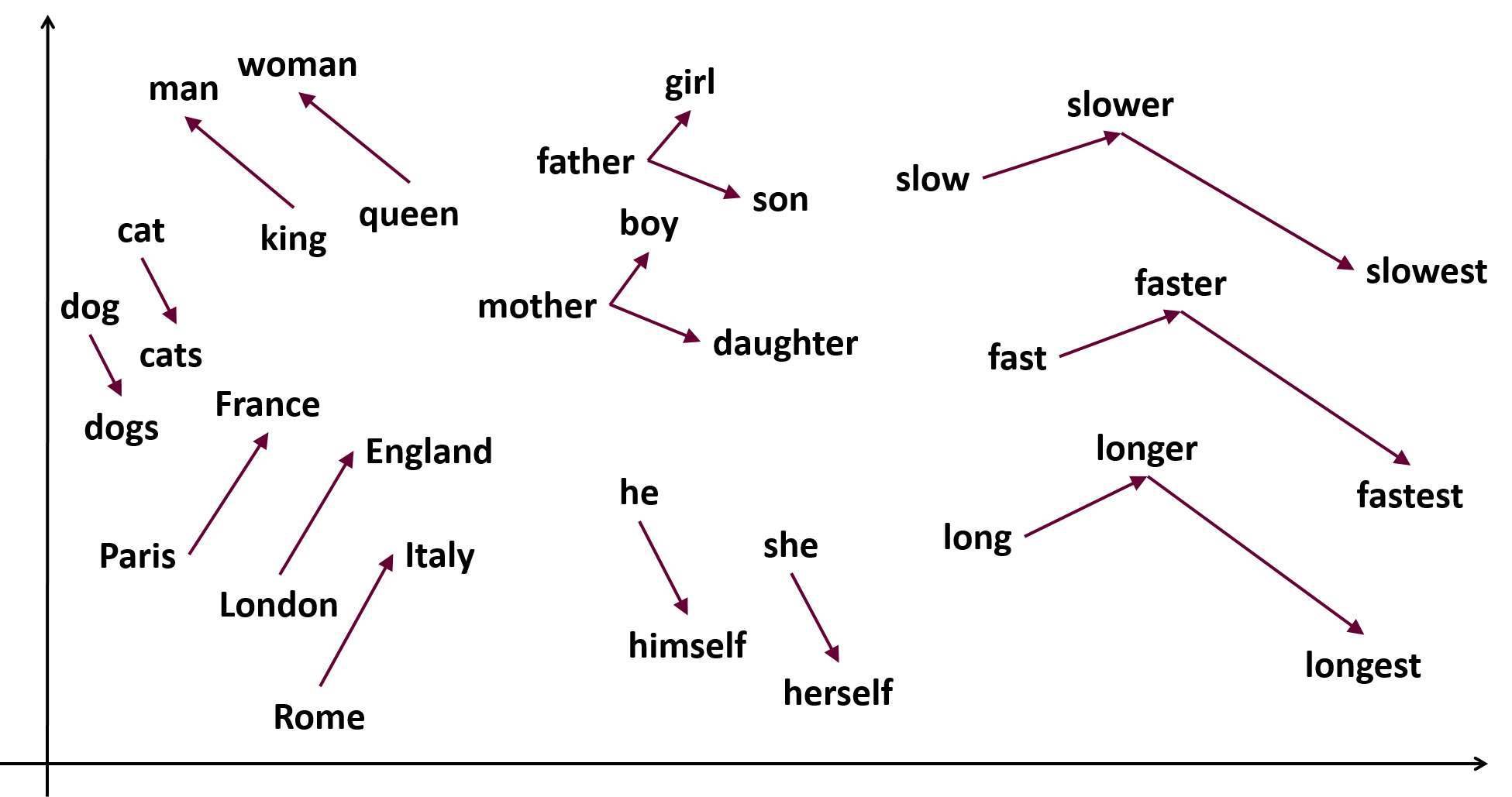
The idea being that since we know the entities in a question (both the term and the label) we can query our datasets to make predictions of who might have a connection based on the relationships found in an unsupervised model from a larger dataset.
It becomes even more interesting when you factor in that Word2Vec can also perform mathematical operations to determine the resulting point. As we improve our tagging of text it might be possible to create positive and negative terms when searching for the most similar results.
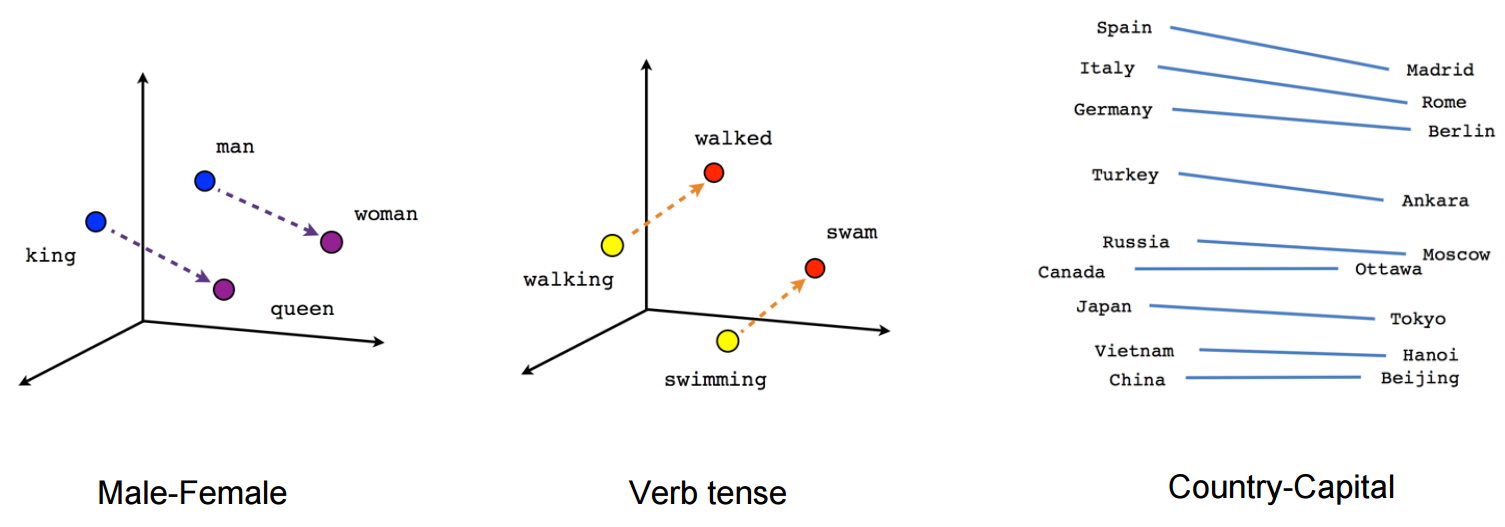
Conclusion
This post has been a bit abstract mostly because I haven’t actually implemented any of the things I mentioned above. After spending the last few months working on document classification and working with Spacy I was reminded of this previous project and thought I should log my initial ideas on solving this problem again.
Sources:
Model: https://codepen.io/explosion/pen/991f245ef90debb78c8fc369294f75ad
Image: https://www.samyzaf.com/ML/nlp/word2vec2.png
Image: https://www.tensorflow.org/tutorials/representation/word2vec